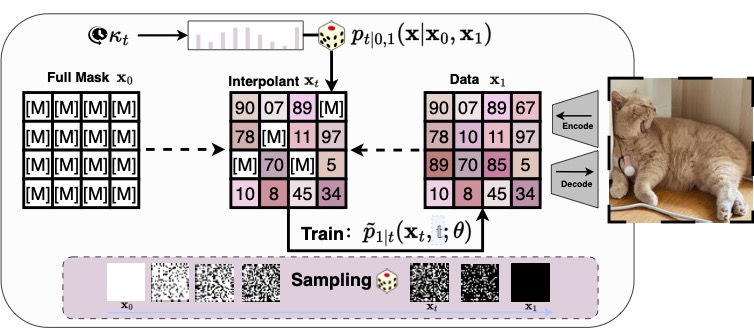
@inproceedings{maskflow,title={MaskFlow: Discrete Flows for Flexible and Efficient Long Video Generation},author={Fuest, Michael and Hu, Vincent Tao and Ommer, Björn},year={2025},booktitle={Arxiv},preview1111={./mask.jpg},repostar={CompVis/maskflow}}
@inproceedings{hu24mask,title={[MASK] is All You Need},author={Hu, Vincent Tao and Ommer, Björn},year={2024},booktitle={Arxiv},repostar={CompVis/discrete-interpolants}}
Scaling Image Tokenizers with Grouped Spherical Quantization
Jiangtao Wang, Zhen Qin, Yifan Zhang, and 4 more authors
@article{wang2024scaling,title={Scaling Image Tokenizers with Grouped Spherical Quantization},author={Wang, Jiangtao and Qin, Zhen and Zhang, Yifan and Hu, Vincent Tao and Ommer, Bj{\"o}rn and Briq, Rania and Kesselheim, Stefan},booktitle={Arxiv},year={2024},note={},repostar={HelmholtzAI-FZJ/flex_gen}}
Guided Flow Vision Transformer from Self-Supervised Diffusion Features
Vincent Tao Hu, Yunlu Chen, Mathilde Caron, and 3 more authors
@inproceedings{sgfm,title={Guided Flow Vision Transformer from Self-Supervised Diffusion Features},author={Hu, Vincent Tao and Chen, Yunlu and Caron, Mathilde and Asano, Yuki M. and Snoek, Cees G.M. and Ommer, Björn},year={2024},note={},booktitle={Arxiv},repostar={dongzhuoyao/sgfm}}
Motion Flow Matching for Human Motion Synthesis and Editing
Vincent Tao Hu, Wenzhe Yin, Pingchuan Ma, and 7 more authors
@inproceedings{motionfm,title={Motion Flow Matching for Human Motion Synthesis and Editing},author={Hu, Vincent Tao and Yin, Wenzhe and Ma, Pingchuan and Chen, Yunlu and Fernando, Basura and Asano, Yuki M. and Gavves, Efstratios and Mettes, Pascal and Ommer, Björn and Snoek, Cees G.M.},year={2024},note1={},booktitle={Arxiv},repostar={dongzhuoyao/motionfm}}
Training Class-Imbalanced Diffusion Model Via Overlap Optimization
Divin Yan, Lu Qi, Vincent Tao Hu, and 2 more authors
@inproceedings{constrastivediffusion,title={Training Class-Imbalanced Diffusion Model Via Overlap Optimization},author={Yan, Divin and Qi, Lu and Hu, Vincent Tao and Yang, Ming-Hsuan and Tang, Meng},year={2024},note={},booktitle={Arxiv},}
2026
CVPR
Guiding Token-Sparse Diffusion Models
Felix Krause, Stefan Andreas Baumann, Johannes Schusterbauer, and 4 more authors
@inproceedings{krause2026guiding,title={Guiding Token-Sparse Diffusion Models},author={Krause, Felix and Baumann, Stefan Andreas and Schusterbauer, Johannes and Grebenkova, Olga and Gui, Ming and Hu, Vincent Tao and Ommer, Björn},year={2026},booktitle={CVPR},repostar={CompVis/tread}}
Purrception: Variational Flow Matching for Vector-Quantized Image Generation
Răzvan-Andrei Matișan, Vincent Tao Hu, Grigory Bartosh, and 6 more authors
@inproceedings{maticsan2026purrception,title={Purrception: Variational Flow Matching for Vector-Quantized Image Generation},author={Matișan, Răzvan-Andrei and Hu, Vincent Tao and Bartosh, Grigory and Ommer, Björn and Snoek, Cees G.M. and Welling, Max and van de Meent, Jan-Willem and Derakhshani, Mohammad Mahdi and Eijkelboom, Floor},year={2026},booktitle={ICLR},}
Diffusion Models and Representation Learning: A Survey
Michael Fuest, Pingchuan Ma, Ming Gui, and 3 more authors
In T-PAMI, 2026
The interplay between diffusion models and representation learning
@inproceedings{diffusion_rl_survey,title={Diffusion Models and Representation Learning: A Survey},author={Fuest, Michael and Ma, Pingchuan and Gui, Ming and Fischer, Johannes and Hu, Vincent Tao and Ommer, Bjorn},year={2026},note={The interplay between diffusion models and representation learning},booktitle={T-PAMI},repostar={dongzhuoyao/Diffusion-Representation-Learning-Survey-Taxonomy}}
2025
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
Felix Krause, Timy Phan, Ming Gui, and 3 more authors
@inproceedings{tread,title={TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training},author={Krause, Felix and Phan, Timy and Gui, Ming and Baumann, Stefan Andreas and Hu, Vincent Tao and Ommer, Björn},year={2025},note11={Skipping layers to boost training convergence},booktitle={ICCV},highlight111={Oral},repostar={CompVis/tread}}
Stochastic Interpolants for Revealing Stylistic Flows across the History of Art
Pingchuan Ma, Ming Gui, Johannes Schusterbauer, and 4 more authors
@inproceedings{artflow,title={Stochastic Interpolants for Revealing Stylistic Flows across the History of Art},author={Ma, Pingchuan and Gui, Ming and Schusterbauer, Johannes and Yang, Xiaopei and Grebenkova, Olga and Hu, Vincent Tao and Ommer, Björn},year={2025},booktitle={ICCV},repostar={CompVis/Art-fm}}
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, and 3 more authors
@inproceedings{baumann2024attributecontrol,title={{C}ontinuous, {S}ubject-{S}pecific {A}ttribute {C}ontrol in {T}2{I} {M}odels by {I}dentifying {S}emantic {D}irections},author={Baumann, Stefan Andreas and Krause, Felix and Neumayr, Michael and Stracke, Nick and Hu, Vincent Tao and Ommer, Björn},year={2025},note={Prompt Editing in T2I models},booktitle={CVPR},repostar={CompVis/attribute-control}}
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Eslam Mohamed BAKR, Liangbing Zhao, Vincent Tao Hu, and 3 more authors
@inproceedings{ToddlerDiffusion,title={ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model},author={BAKR, Eslam Mohamed and Zhao, Liangbing and Hu, Vincent Tao and Cord, Matthieu and Perez, Patrick and Elhoseiny, Mohamed},year={2025},booktitle={ICLR},repostar={toddlerdiffusion/code}}
DepthFM: Fast Monocular Depth Estimation with Flow Matching
Ming Gui, Johannes S. Fischer, Ulrich Prestel, and 6 more authors
In AAAI, 2025
An exploration of flow matching for blazing fast and zero-shot depth estimation
@inproceedings{depthfm,title={DepthFM: Fast Monocular Depth Estimation with Flow Matching},author={Gui, Ming and Fischer, Johannes S. and Prestel, Ulrich and Ma, Pingchuan and Kotovenko, Dmytro and Grebenkova, Olga and Baumann, Stefan A. and Hu, Vincent Tao and Ommer, Björn},year={2025},note={An exploration of flow matching for blazing fast and zero-shot depth estimation},booktitle={AAAI},highlight={Oral},repostar={CompVis/depth-fm}}
Does VLM Classification Benefit from LLM Description Semantics?
Pingchuan Ma, Lennart Rietdorf, Dmytro Kotovenko, and 2 more authors
@inproceedings{fundel2025distilldift,title={Distillation of Diffusion Features for Semantic Correspondence},author={Fundel, Frank and Schusterbauer, Johannes and Hu, Vincent Tao and Ommer, Björn},year={2025},note={},booktitle={WACV},repostar={CompVis/DistillDIFT}}
2024
ZigMa: A DiT-style Zigzag Mamba Diffusion Model
Vincent Tao Hu, Stefan Andreas Baumann, Ming Gui, and 4 more authors
@inproceedings{hu2024zigmaa,title={ZigMa: A DiT-style Zigzag Mamba Diffusion Model},author={Hu, Vincent Tao and Baumann, Stefan Andreas and Gui, Ming and Grebenkova, Olga and Ma, Pingchuan and Fischer, Johannes and Ommer, Bjorn},year={2024},note={a DiT-style Mamba-based diffusion models },booktitle={ECCV},repostar={CompVis/zigma}}
Boosting Latent Diffusion with Flow Matching
Johannes S. Fischer, Ming Gui, Pingchuan Ma, and 4 more authors
@inproceedings{fischer2023boosting,title={Boosting Latent Diffusion with Flow Matching},author={Fischer, Johannes S. and Gui, Ming and Ma, Pingchuan and Stracke, Nick and Baumann, Stefan A. and Hu, Vincent Tao and Ommer, Bjorn},year={2024},note={flow matching for super-resolution},booktitle={ECCV},highlight={Oral},repostar={CompVis/fm-boosting}}
Latent Space Editing in Transformer-based Flow Matching
Vincent Tao Hu, David W Zhang, Pascal Mettes, and 3 more authors
In AAAI 2024. Also appear in ICML 2023 Workshop, New Frontiers in Learning, Control, and Dynamical Systems, 2024
@inproceedings{hulfm,title={Latent Space Editing in Transformer-based Flow Matching},author={Hu, Vincent Tao and Zhang, David W and Mettes, Pascal and Tang, Meng and Zhao, Deli and Snoek, Cees G.M.},year={2024},note={},booktitle={AAAI 2024. Also appear in ICML 2023 Workshop, New Frontiers in Learning, Control, and Dynamical Systems},repostar={dongzhuoyao/uspace}}
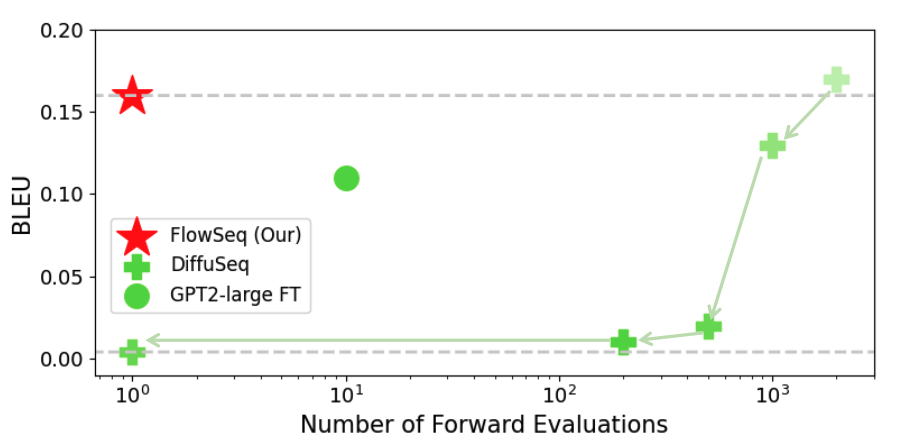
Flow Matching for Conditional Text Generation in a Few Sampling Steps
Vincent Tao Hu, Di Wu, Yuki M. Asano, and 4 more authors
@inproceedings{huflowseq,title={Flow Matching for Conditional Text Generation in a Few Sampling Steps},author={Hu, Vincent Tao and Wu, Di and Asano, Yuki M. and Mettes, Pascal and Fernando, Basura and Ommer, Björn and Snoek, Cees G.M.},year={2024},booktitle={EACL},note={Flow Matching for text generation},selectedddd={true},repostar={dongzhuoyao/flowseq}}
2023
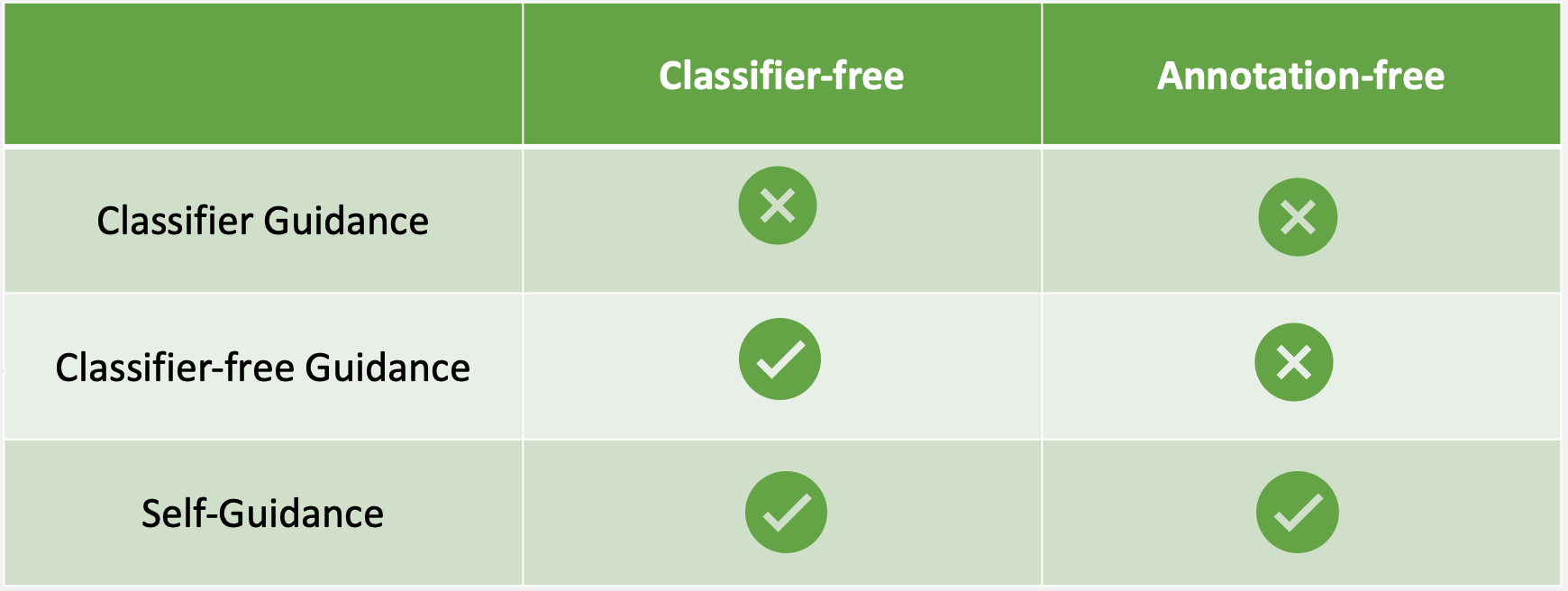
Self-Guided Diffusion Models
Tao Hu*, David W Zhang*, Yuki M. Asano, and 2 more authors
In CVPR, 2023
A bridge between the community of self-supervised learning and diffusion models. Short version to appear in NeurIPS 2022 Workshop on Score-Based Methods and NeurIPS 2022 Workshop Self-Supervised Learning Theory and Practice.
@inproceedings{hu2022selfguided,title={Self-Guided Diffusion Models},author={Hu*, Tao and Zhang*, David W and Asano, Yuki M. and Burghouts, Gertjan J. and Snoek, Cees G.M.},year={2023},booktitle={CVPR},note={A bridge between the community of self-supervised learning and diffusion models. Short version to appear in NeurIPS 2022 Workshop on Score-Based Methods and
NeurIPS 2022 Workshop Self-Supervised Learning Theory and Practice.},repostar={dongzhuoyao/self-guided-diffusion-models}}
2021
Self-supervised Video Representation Learning with Cross-Stream Prototypical Contrasting
Martine Toering, Ioannis Gatopoulos, Maarten Stol, and 1 more author
In WACV, 2021
Improve video representation by constrasting Prototypical features.
@inproceedings{toering2022self,title={Self-supervised Video Representation Learning with Cross-Stream Prototypical Contrasting},author={Toering, Martine and Gatopoulos, Ioannis and Stol, Maarten and Hu, Tao},booktitle={WACV},year={2021},note={Improve video representation by constrasting Prototypical features.},repostar={martinetoering/ViCC}}
2020
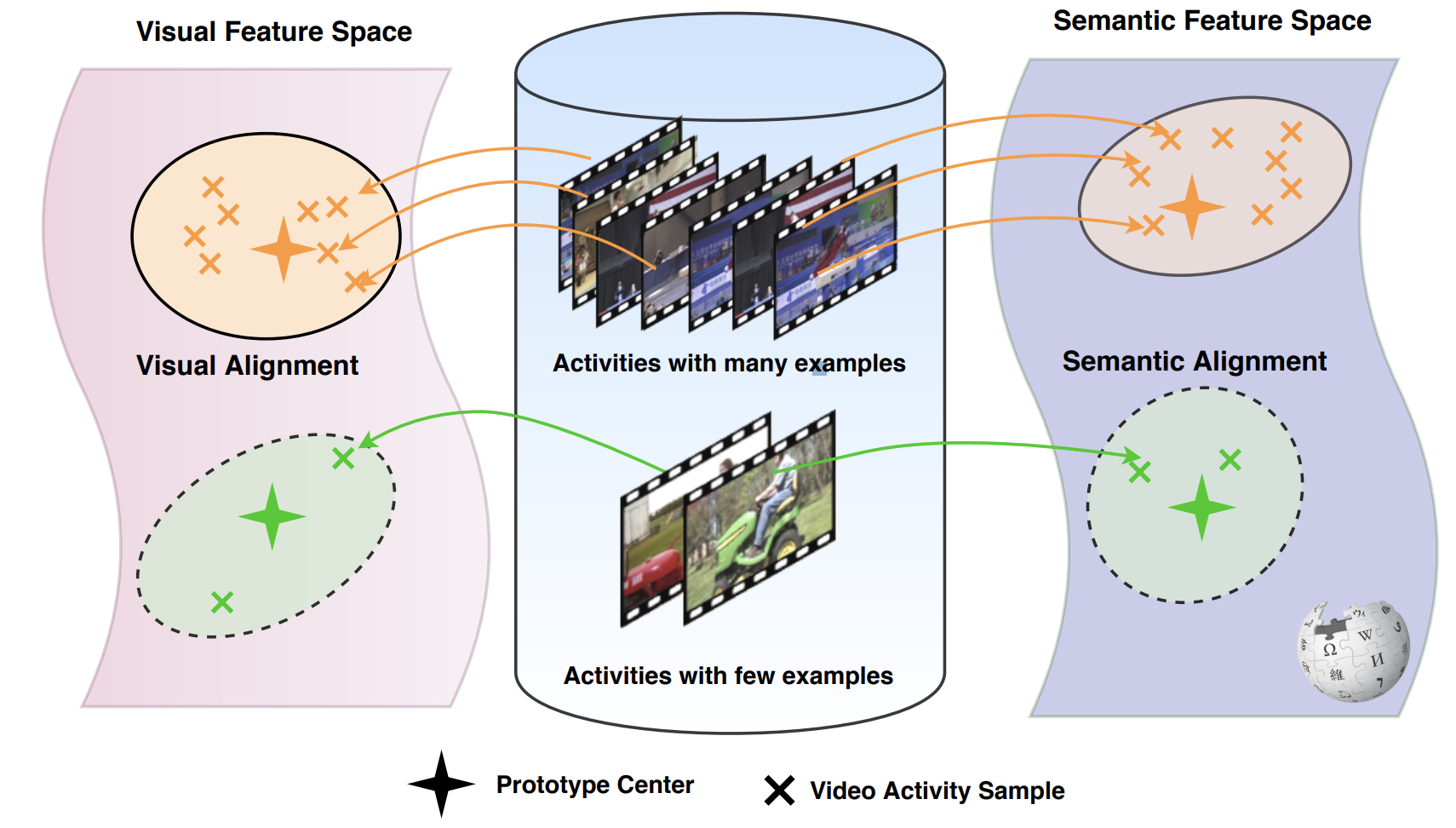
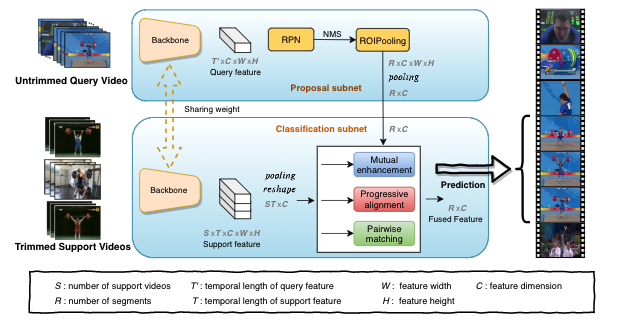
Localizing the Common Action Among a Few Videos
Pengwan Yang*, Tao Hu*, Pascal Mettes, and 1 more author
In European Conference on Computer Vision(ECCV), 2020
Localizing the temporal extent of an action in a long untrimmed video by attention techniques.
@inproceedings{YangECCV20,author={Yang*, Pengwan and Hu*, Tao and Mettes, Pascal and Snoek, Cees G.M.},title={Localizing the Common Action Among a Few Videos},booktitle={European Conference on Computer Vision(ECCV)},year={2020},note={Localizing the temporal extent of an action in a long untrimmed video by attention techniques.},repostar={PengWan-Yang/commonLocalization}}
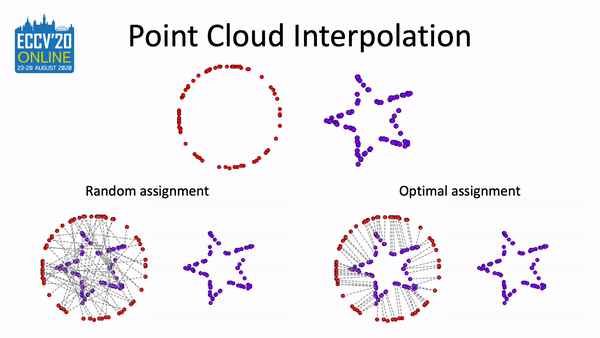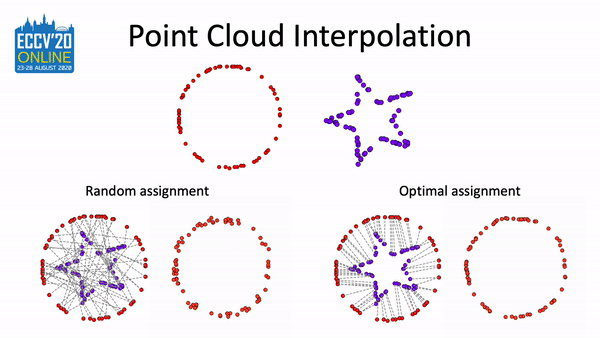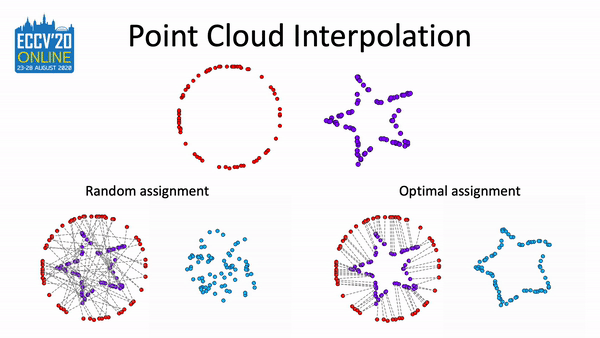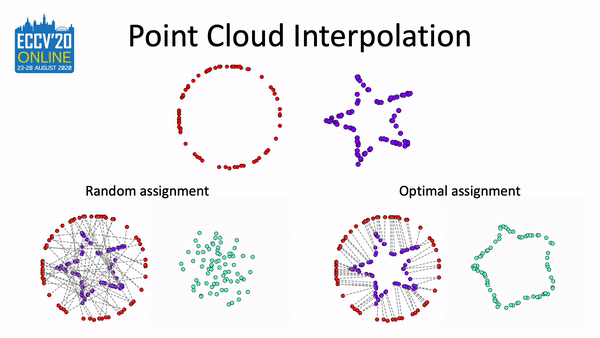
Pointmixup: Augmentation for point clouds
Yunlu Chen*, Tao Hu*, Efstratios Gavves, and 4 more authors
In European Conference on Computer Vision(ECCV), 2020
A simple augmentation method based on MixUp to boost the performance on related tasks of point cloud.
@inproceedings{chen2020pointmixup,title={Pointmixup: Augmentation for point clouds},author={Chen*, Yunlu and Hu*, Tao and Gavves, Efstratios and Mensink, Thomas and Mettes, Pascal and Yang, Pengwan and Snoek, Cees G.M.},booktitle={European Conference on Computer Vision(ECCV)},highlight={Spotlight},year={2020},note={A simple augmentation method based on MixUp to boost the performance on related tasks of point cloud.},repostar={yunlu-chen/PointMixup}}
2019
Attention-based Multi-Context Guiding for Few-Shot Semantic Segmentation
Tao Hu, Pengwan Yang, Chiliang Zhang, and 3 more authors
In AAAI, 2019
Solve the few-shot segmentation problem by applying attention in multi-scales.
@inproceedings{tao2018fss,title={Attention-based Multi-Context Guiding for Few-Shot Semantic Segmentation},author={Hu, Tao and Yang, Pengwan and Zhang, Chiliang and Yu, Gang and Mu, Yadong and Snoek, Cees G.M.},booktitle={AAAI},highlight={Spotlight},year={2019},note={Solve the few-shot segmentation problem by applying attention in multi-scales.},}
SILCO: Show a Few Images, Localize the Common Object
Tao Hu, Pascal Mettes, Jia-Hong Huang, and 1 more author
In International Conference on Computer Vision(ICCV), 2019
Design a graph network and apply attention on them to solve the problem of common object localization.
@inproceedings{silco2019,title={SILCO: Show a Few Images, Localize the Common Object},author={Hu, Tao and Mettes, Pascal and Huang, Jia-Hong and Snoek, Cees G.M.},booktitle={International Conference on Computer Vision(ICCV)},year={2019},note={Design a graph network and apply attention on them to solve the problem of common object localization.},}