Semi-supervised learning
Basic solution
Normalization flow-based
Train:
\[L(\theta) = \sum_{(x_{i},y_{i}) \in labelled} log p_{\theta} (x_{i}, y_{i}) + \sum_{x_{j} \in unlabelled} log p_{\theta}(x_{j})\]\(p_{\theta} (x_{i}, y_{i})\) can be solved by(1). Hybrid models1 or (2). further decomposed as\(p_{\theta} (x_{i}, y_{i}) = p_{\theta}(y_{i}) * p_{\theta}(x_{i}|y_{i})\)
(1). Hybrid model decompose \(p_{\theta} (x, y)\) to \(p_{\theta}(x)*p_{\theta}(y|x)\)
This paper use Generalized Linear Models(GLM) to model \(p(y_{i}|x_{i})\), P(x) is modeled by Normalization Flow.
(2). \(p(x)\) is modeled by normalization flow, \(p(y|x)\) is modeled by conditional normalization flow(novelty lies in).
Testing: \(p(y|x) = p(x,y)/p(x)\)
Semi-supervised image classification
Summary from FixMatch:
EntMin: Semi-supervised learning by entropy minimization,NIPS05
- interesting and simple idea, high citation.

sceenshot from S4L: Self-Supervised Semi-Supervised Learning,ICCV19
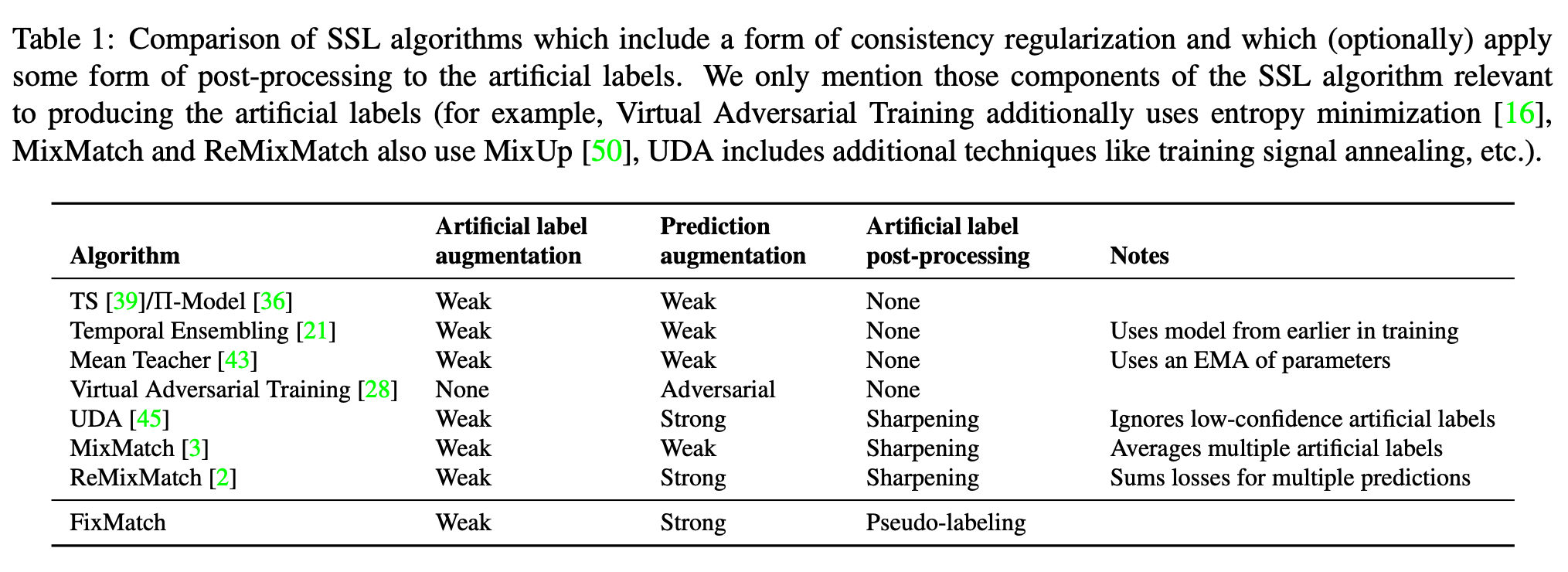
Temporal Ensembling for Semi-Supervised Learning,ICLR17
\(z_{i}\) is \(N \times C\), will move averaged to \(\tilde{z_{i}}\), check alg 2 in the paper.
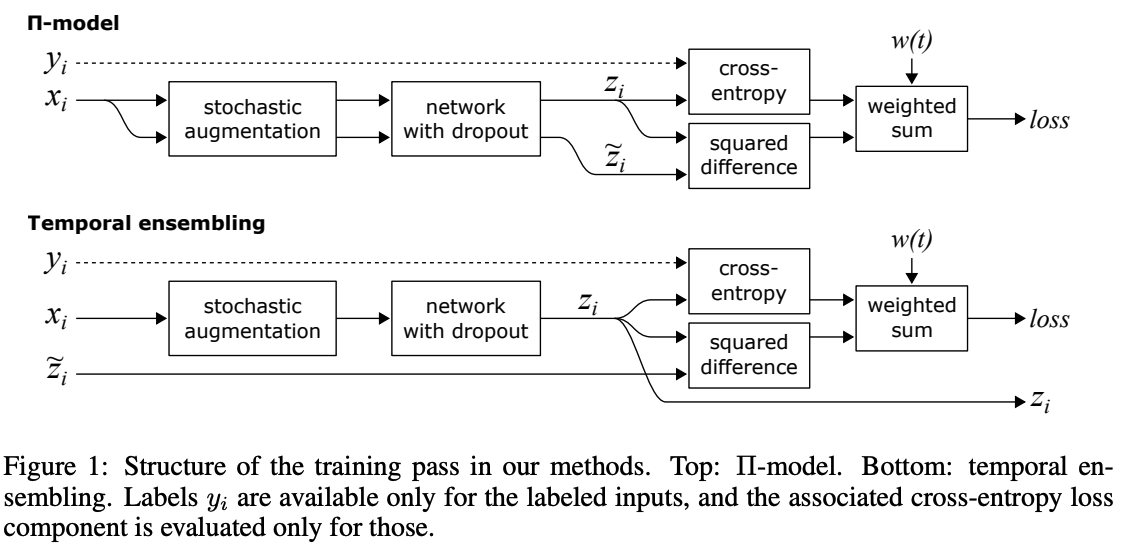
Motivated by Temporal Emsembling. Temporal Emsembling is moving averaged on output, mean teacher is moving averaged on network parameters.
Teacher model is the moving average of student model, do not reverse.
mean squared error (MSE) as our consistency cost function, MSE is better than KL-divergence experimentally.
Three different noises \(\upeta\) are considered: The model architecture is a 13-layer convolutional neural network (ConvNet) with three types of noise: random translations and horizontal flips of the input images, Gaussian noise on the input layer, and dropout applied within the network.
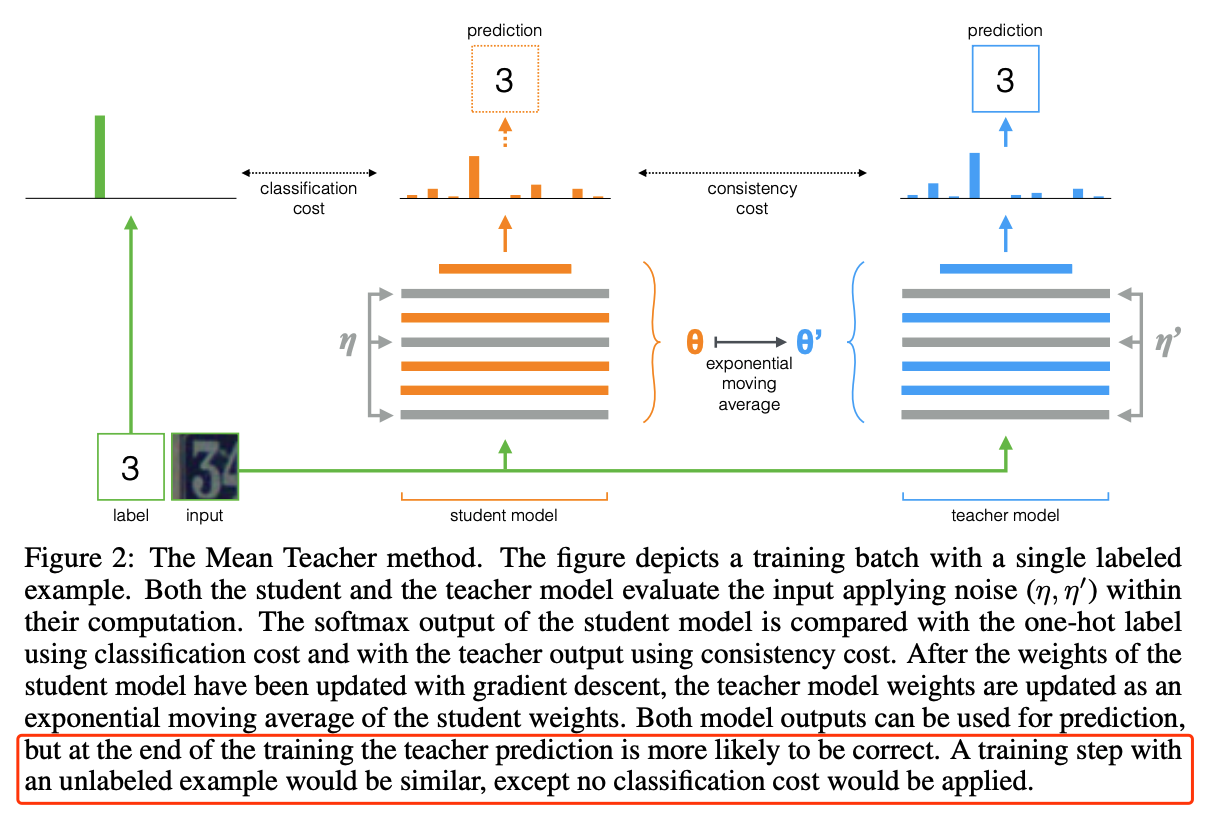
Label Propagation for Deep Semi-supervised Learning,CVPR19
Based on Mean Teacher.

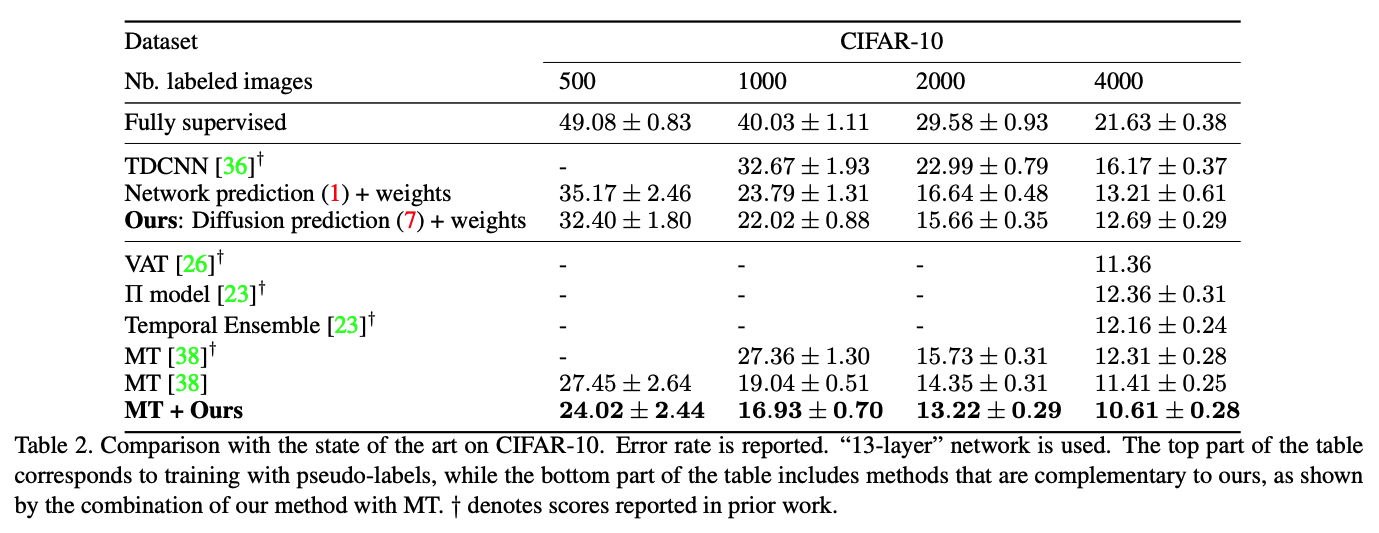
Realistic Evaluation of Deep Semi-Supervised Learning Algorithms,NeurIPS18
P.4 Considering Class Distribution Mismatch. consider the following example: Say you are trying to train a model to distinguish between ten different faces, but you only have a few images for each of these ten faces. As a result, you augment your dataset with a large unlabeled dataset of images of random people’s faces. In this case, it is extremely unlikely that any of the images in DUL will be one of the ten people the model is trained to classify.
Building One-Shot Semi-supervised (BOSS) Learning up to Fully Supervised Performance,Arxiv2006
motivated by barely-supervised learniing in FixMatch.
A combination of fixmatch, self-training, etc.
MixMatch: A Holistic Approach to Semi-Supervised Learning,NeurIPS19
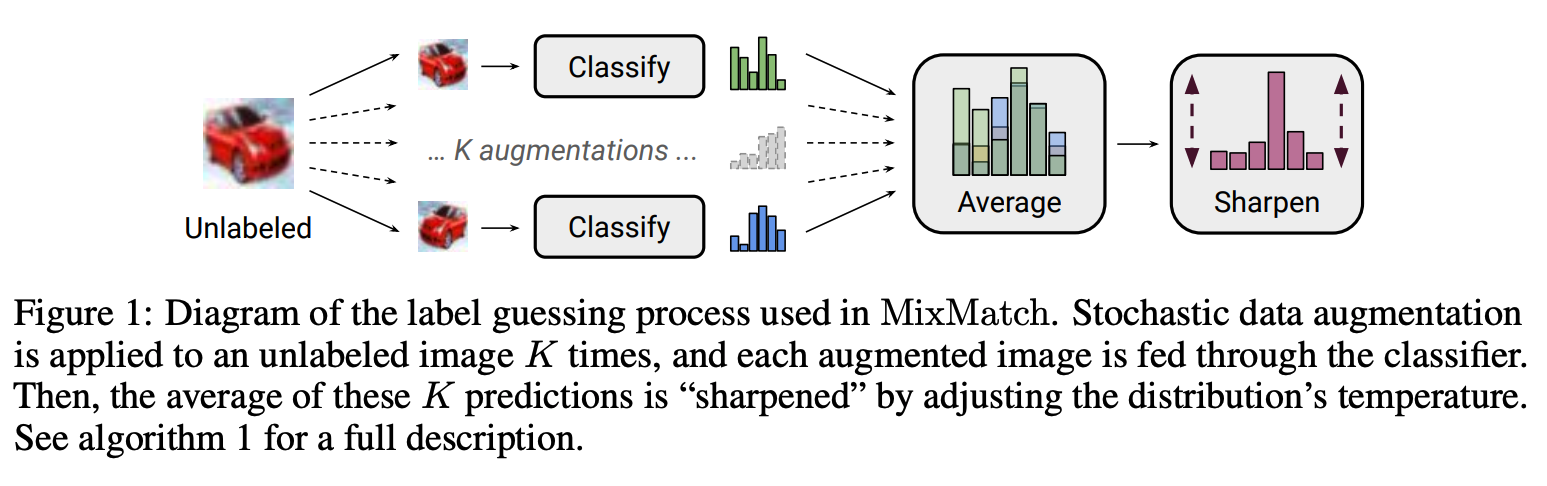

- Table 4 is full of information.
- The relation of privacy-preserving is also interesting.
- finicky point:mixup has max function to gurantee the mixed result biases towards labelled image x.
- finicky point: X use shannon-entropy, U use MSE.
- In all experiments, we linearly ramp up λU to its maximum value over the first 16,000 steps of training as is common practice.
- Interleave to stablize the BN witch: https://github.com/YU1ut/MixMatch-pytorch/issues/20#issuecomment-583770295
ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring,ICLR20

Unsupervised Data Augmentation (UDA)
TODO
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence,NeurIPS20
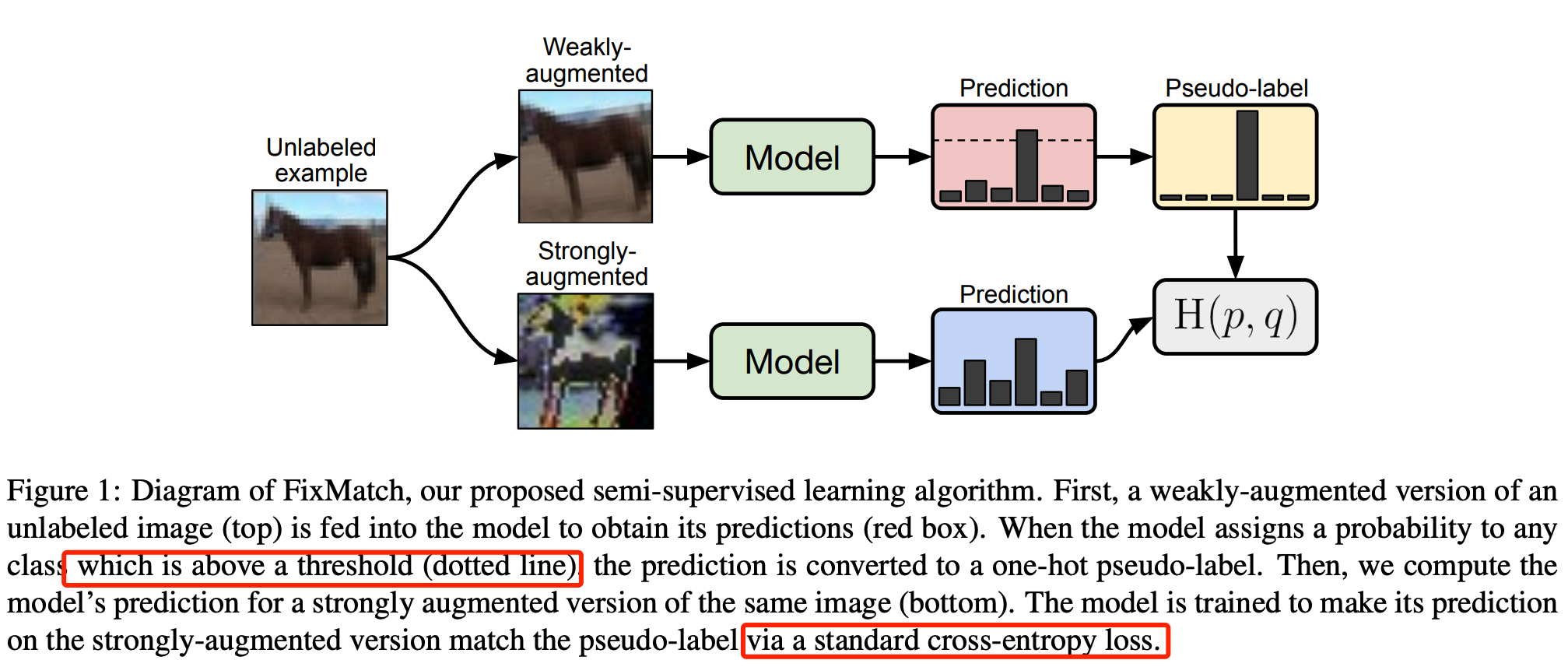
- weak-augmentation-> only flip-and-shift data augmentation.
- stron-augmentation-> Inspired by UDA [45] and ReMixMatch [2], we leverage CutOut [13], CTAugment [2], and RandAugment [10] for strong augmentation, which all produce heavily distorted versions of a given image.
- Why thresholding?Inspired by UDA [45] and ReMixMatch [2], we leverage CutOut [13], CTAugment [2], and RandAugment [10] for strong augmentation, which all produce heavily distorted versions of a given image.
- basic experimental choices that are often ignored or not reported when new SSL methods are proposed (such as the optimizer or learning rate schedule) because we found that they can have an outsized impact on performance.
- weak,weak doesn’t work; weak,strong works.
- The loss is composed of supervised loss and unsupervised loss. the weight of unsupervised loss should increase gradually by annealing.
- Detail matters, weight decay regularization is particularly important.
- SGD is better than Adam. Table 5.
- use a cosine learning rate decay,Table 6.
- In summary, we observe that swapping pseudo-labeling for sharpening and thresholding would introduce a new hyperparameter while achieving no better performance.
- Of the aforementioned work, FixMatch bears the closest resemblance to two recent algorithms: Unsupervised Data Augmentation (UDA) [45] and ReMixMatch [2].
- …………. We find that to obtain strong results, especially in the limited-label regime, certain design choices are often underemphasized – most importantly, weight decay and the choice of optimizer. The importance of these factors means that even when controlling for model architecture as is recommended in [31], the same technique can not always be directly compared across different implementations.
Rethinking Semi–Supervised Learning in VAEs,Arxiv2006
Semisupervised knowledge transfer for deep learning from private training data.ICLR17 best paper
relate SSL and differential privacy
Improved Regularization of Convolutional Neural Networks with Cutout,Arxiv17
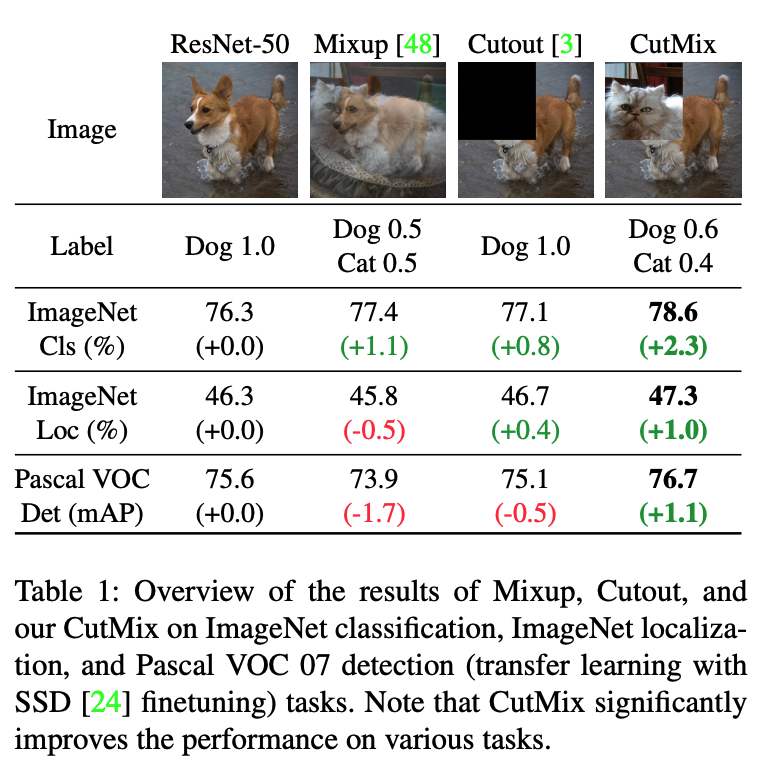
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features,ICCV19,oral
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty,ICLR20
Semi-supervised semantic segmentation
Consistency regularization
Consistency regularization (Sajjadi et al., 2016b; Laine & Aila, 2017; Miyato et al., 2017; Oliver et al., 2018) describes a class of semi-supervised learning algorithms that have yielded state-ofthe-art results in semi-supervised classification, while being conceptually simple and often easy to implement. The key idea is to encourage the network to give consistent predictions for unlabeled inputs that are perturbed in various ways.
Semi-Supervised Semantic Segmentation with Cross-Consistency Training,CVPR20
- pertubation function is important
- Semi-Supervised Domain Adaptation, and combintation with image-level labels is a bonus
Adversarial Learning for Semi-Supervised Semantic Segmentation,BMVC18
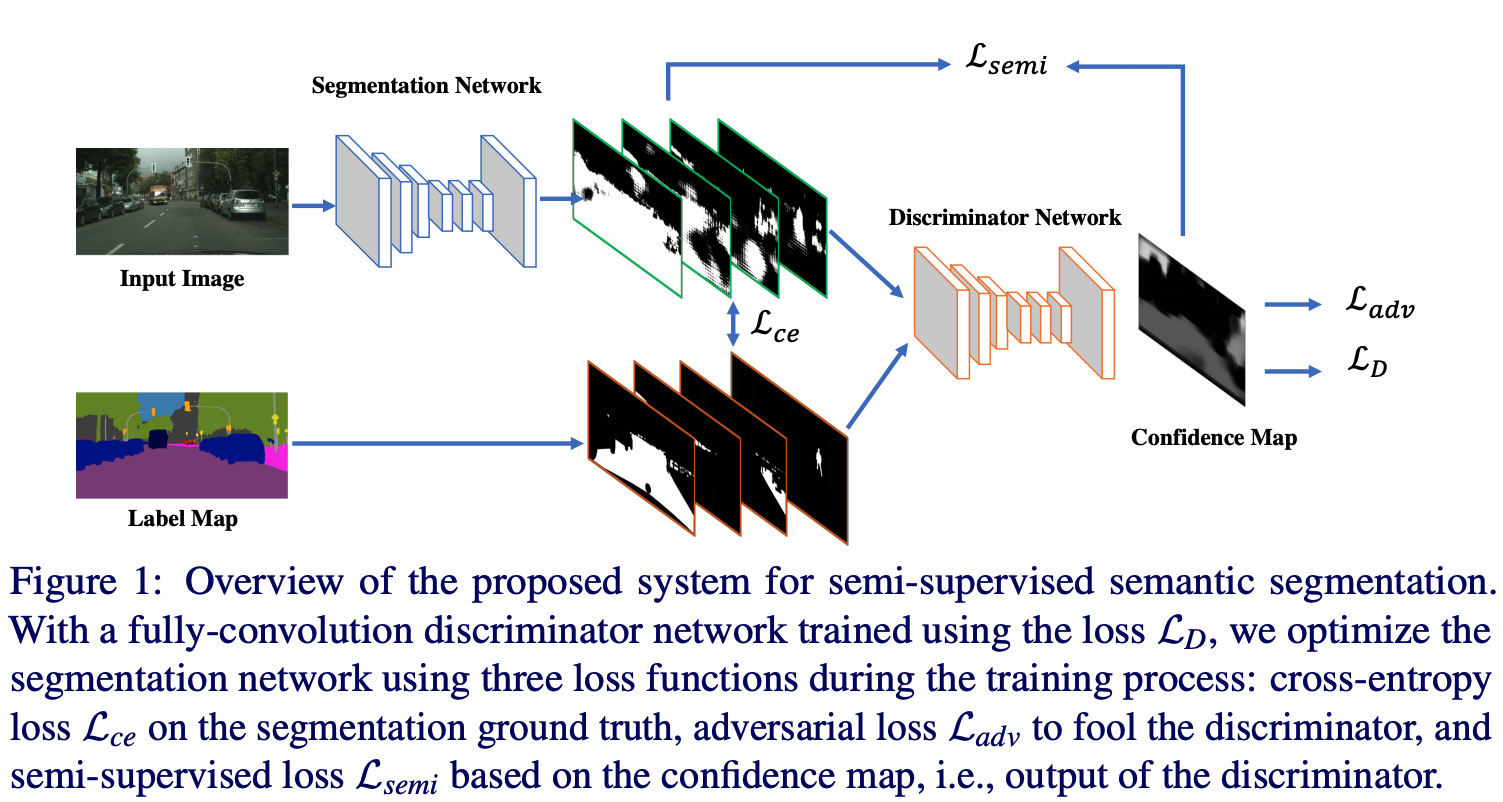
Pay more attention to \(L_{semi}\) loss, by thresholding the output of discriminator network to construct a psydo label.
CowMix, Semi-supervised semantic segmentation needs strong, high-dimensional perturbations
The use of a rectangular mask restricts the dimensionality of the perturbations that CutOut and CutMix can produce. Intuitively, a more complex mask that has more degrees of freedom should provide better exploration of the plausible input space. We propose combining the semantic CutOut and CutMix regularizers introduced above with a novel mask generation method, giving rise to two regularization methods that we dub CowOut and CowMix due to the Friesian cow -like texture of the masks.
Semi-supervised detection
Consistency-based Semi-supervised Learning for Object Detection,NeurIPS19
A Simple Semi-Supervised Learning Framework for Object Detection,Arxiv2005
Kihyuk Sohn
Footnotes
-
Hybrid Models with Deep and Invertible Features, ICML19. ↩